

Server Deployment
Automation: Why Reliable Deployments Become Difficult at Scale
Server Deployment Automation: Why Reliable Deployments Become Difficult at
Scale Server Deployment Automation helps DevOps teams improve
Server Deployment Automation: Why Reliable Deployments Become Difficult at Scale
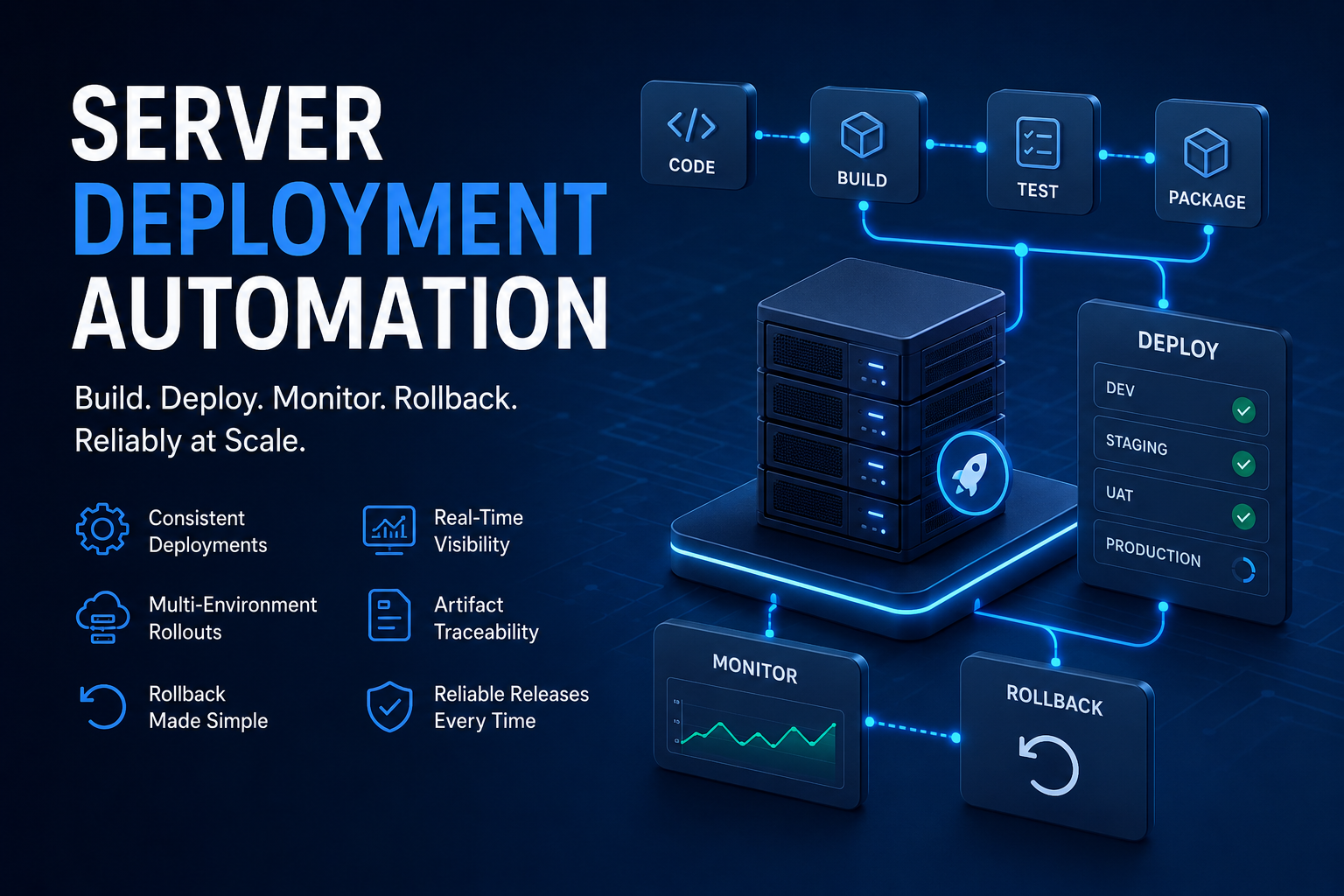
Server Deployment Automation helps DevOps teams improve deployment reliability, rollout consistency, rollback handling, runtime validation, and release visibility across modern infrastructure environments. It becomes far more important once infrastructure starts growing beyond a few applications and environments. Most deployment workflows look manageable in the beginning. A shell script copies files to a server, restarts a service, and the release is complete. For smaller teams, that setup works surprisingly well for a while.
Then the infrastructure grows.
Another environment gets added. Multiple teams start deploying services independently. Production configurations slowly drift away from staging. Rollback procedures become more complicated because deployments now affect runtime variables, dependencies, background workers, and infrastructure state at the same time.
At that point, deployments stop being simple automation tasks.
They become operational workflows that require consistency, visibility, rollback reliability, artifact tracking, and structured release coordination.
This is where modern Server Deployment Automation becomes essential for DevOps teams operating cloud-native infrastructure and large-scale release environments.
Why Deployments Start Becoming Unpredictable
One of the biggest misconceptions in DevOps is that deployment failures usually happen because the application itself is broken.
In reality, most deployment issues are caused by everything around the application.
A deployment may technically succeed while still leaving production unstable because:
- runtime configurations behave differently,
- environment variables changed unexpectedly,
- the wrong artifact version was deployed,
- dependencies restarted in the wrong order,
- or rollback restored only part of the previous release state.
These problems rarely appear all at once.
They build slowly over time as infrastructure complexity increases.
This is why deployment instability often surprises engineering teams. Everything may appear manageable until suddenly deployments no longer feel predictable across environments.
That uncertainty becomes one of the biggest operational risks in modern software delivery.
Traditional Deployment Scripts Eventually Become Difficult to Maintain
Most teams begin with lightweight deployment scripts because they are fast to create and easy to understand initially.
A few shell scripts plus SSH access can take an engineering team surprisingly far.
The problem is that deployment workflows rarely stay simple.
Over time the scripts accumulate operational responsibilities such as:
- runtime validation,
- artifact synchronization,
- health checks,
- rollback handling,
- cleanup operations,
- infrastructure preparation,
- and deployment approvals.
Eventually deployments become dependent on:
- old scripts spread across repositories,
- CI/CD configuration,
- manually updated runtime settings,
- and specific engineers who understand how production behaves internally.
At that stage, deployment reliability becomes tightly coupled to tribal operational knowledge instead of structured release workflows.
This creates long-term operational fragility.
Why Server Deployment Automation Matters in Modern DevOps
Modern DevOps environments require much more than simply automating deployment execution.
Teams need deployment workflows that are:
- repeatable,
- observable,
- rollback-aware,
- artifact-aware,
- and operationally consistent across environments.
This is the real value of Server Deployment Automation.
A structured deployment workflow helps engineering teams:
- standardize deployment stages,
- improve rollback reliability,
- reduce release inconsistencies,
- centralize deployment visibility,
- and simplify troubleshooting during production incidents.
As deployment frequency increases, these capabilities become critical for maintaining operational stability.
Deployment Visibility Is More Important Than Most Teams Realize
A lot of deployment tooling focuses heavily on automation speed.
But for most engineering teams, visibility matters more than raw deployment speed.
During a failed release, engineers need answers to practical operational questions:
- Which deployment phase failed?
- Which artifact version is running?
- Did the rollback start successfully?
- Which environment is affected?
- Which runtime checks failed?
- Did the deployment partially complete?
Without centralized deployment visibility, troubleshooting becomes slow and stressful very quickly.
This becomes especially painful during production incidents where teams are trying to recover services while simultaneously reconstructing what actually happened during rollout execution.
Modern Server Deployment Automation therefore focuses heavily on:
- deployment status tracking,
- execution visibility,
- runtime monitoring,
- deployment logs,
- rollout timelines,
- and operational traceability.
These capabilities dramatically improve deployment reliability in large-scale DevOps environments.
Artifact Management Quietly Becomes a Major Deployment Problem
Artifacts are often underestimated in deployment discussions.
At smaller scale, teams usually assume the latest build is automatically the correct release package.
That assumption eventually breaks.
As deployments increase across environments, engineering teams need reliable artifact traceability:
- which build generated the artifact,
- where it was deployed,
- which version reached production,
- and which release introduced runtime changes.
Without proper artifact awareness, deployments become difficult to debug reliably.
A deployment may technically complete successfully while still deploying:
- outdated packages,
- incorrect binaries,
- or partially generated release artifacts.
This is why modern Server Deployment Automation increasingly integrates artifact tracking directly into deployment workflows.
Rollback Reliability Becomes Critical Under Production Pressure
Rollback discussions often sound straightforward during planning meetings.
“Just redeploy the previous version.”
Real production systems rarely behave that cleanly.
Modern deployments frequently change:
- runtime configurations,
- infrastructure dependencies,
- deployment ordering,
- environment variables,
- service discovery behavior,
- and background processes.
A rollback may restore application binaries while still leaving the environment unstable.
This is why rollback handling cannot be treated as a completely separate emergency process.
Reliable rollback workflows depend heavily on:
- deployment history,
- runtime validation,
- artifact traceability,
- deployment visibility,
- and operational consistency.
Without those things, rollback becomes extremely difficult during production incidents.
Runtime Validation Has Changed Deployment Engineering
Modern deployments no longer end when deployment scripts finish executing.
The deployment is only successful if the environment itself is healthy afterward.
This changes how release workflows operate.
Modern Server Deployment Automation increasingly includes:
- health verification,
- dependency checks,
- API validation,
- infrastructure readiness testing,
- runtime monitoring,
- and post-deployment validation
as part of deployment execution itself.
Many deployment failures only appear after rollout technically completes.
This is why runtime-aware deployment workflows are becoming standard practice across modern DevOps environments.
Why Teams Move Toward Centralized Deployment Workflows
As infrastructure grows, fragmented deployment logic becomes operationally exhausting.
Different environments behave differently. Release visibility becomes inconsistent. Rollback handling varies between services. Troubleshooting requires jumping between CI systems, logs, terminal sessions, and infrastructure consoles.
Eventually engineering teams move toward centralized deployment orchestration because it improves operational consistency.
Centralized Server Deployment Automation helps teams:
- standardize rollout behavior,
- centralize deployment visibility,
- improve troubleshooting,
- maintain release traceability,
- and reduce deployment drift between environments.
This operational consistency improves both deployment reliability and engineering confidence.
Event-Driven Deployments Are Becoming the Standard
Manual deployment execution is slowly disappearing in mature DevOps organizations.
Modern deployment systems increasingly trigger releases automatically based on:
- successful builds,
- repository updates,
- approval completion,
- infrastructure workflows,
- or external automation systems.
This significantly reduces manual coordination overhead while improving release consistency.
The important part is not just automation itself.
It is that the same deployment workflow executes consistently every time instead of depending on engineers manually coordinating release steps under pressure.
As infrastructure complexity grows, event-driven Server Deployment Automation becomes increasingly important for maintaining scalable software delivery operations.
The Future of Server Deployment Automation
Modern deployment engineering is evolving rapidly alongside cloud-native infrastructure and platform engineering practices.
Today’s DevOps teams increasingly require:
- centralized deployment visibility,
- rollback-aware workflows,
- runtime validation,
- artifact-aware deployments,
- multi-stage rollout coordination,
- and integrated operational monitoring.
The future of Server Deployment Automation is not simply about deploying software faster.
It is about building deployment systems that engineers can actually trust during production releases.
Because once infrastructure grows large enough, predictable deployments become one of the most valuable operational advantages an engineering organization can have.
Recent Posts
- The Hidden Cost of Too Many Dashboards: Why Infrastructure Visibility Gets Harder as Systems Grow
- Why Kubernetes Starts Feeling Unpredictable After a Certain Scale
- Server Deployment Automation: Why Reliable Deployments Become Difficult at Scale
- Modernizing Server Build Workflows for Scalable DevOps Operations
- CI/CD Pipeline Chaos: Why Modern DevOps Teams Need Better Workflow Automation