

Why Kubernetes
Starts Feeling Unpredictable After a Certain Scale
Why Kubernetes Starts Feeling Unpredictable After a Certain Scale
Kubernetes Environment Management becomes increasingly difficult
Why Kubernetes Starts Feeling Unpredictable After a Certain Scale
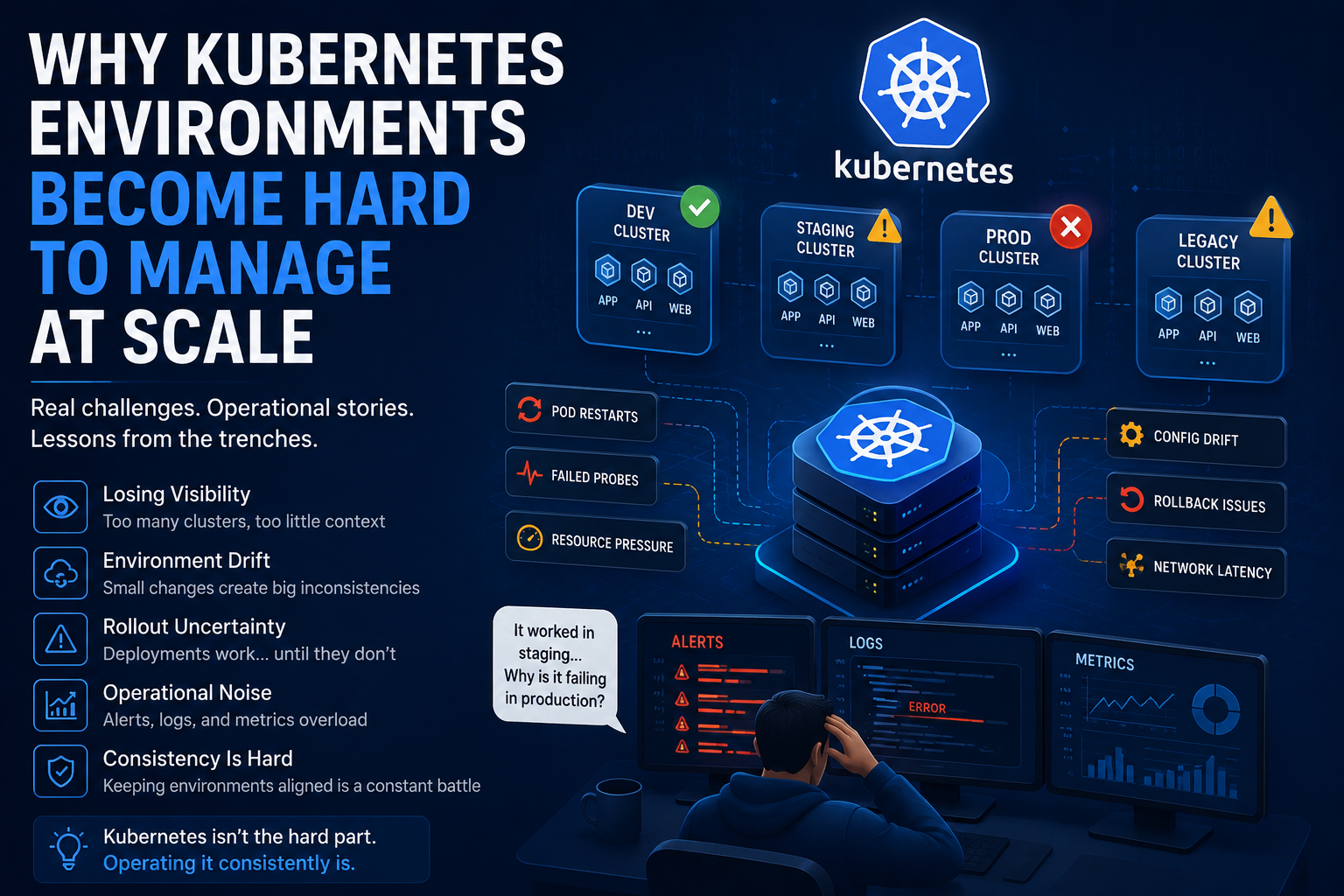
Kubernetes Environment Management becomes increasingly difficult as infrastructure grows, clusters drift apart, deployments behave inconsistently, and operational visibility decreases across environments.
Most teams don’t struggle with Kubernetes in the beginning.
The first cluster usually feels clean, modern, and surprisingly easy compared to managing traditional infrastructure manually. Deployments become faster, scaling workloads feels automatic, and engineers quickly get comfortable with pods, services, ingress rules, and namespaces. For a while, Kubernetes genuinely feels like it removed a lot of operational pain.
Then the environment grows a little more.
Another cluster gets added for staging. Production starts carrying heavier traffic. Different teams begin deploying services independently. One application suddenly needs custom ingress behavior. Somebody manually changes a runtime value during an incident because fixing production quickly matters more than updating infrastructure code properly at that moment.
None of this feels dangerous when it happens.
But several months later, engineers start noticing something uncomfortable: deployments no longer behave consistently across environments.
A rollout that works perfectly in staging behaves differently in production. Pods restart randomly only in one cluster. A service suddenly becomes unstable after scaling even though nothing changed in the application itself. Monitoring dashboards show healthy infrastructure while users continue reporting intermittent failures.
This is usually the point where Kubernetes stops feeling like “container orchestration” and starts becoming an operational reliability problem.
And honestly, this transition happens much earlier than most teams expect.
Kubernetes Is Easy to Learn but Hard to Operate Consistently
One of the biggest misconceptions around Kubernetes is that the hard part is learning Kubernetes itself.
It really isn’t.
Most engineers can learn deployments, services, ingress rules, and Helm charts relatively quickly. The difficult part is operating Kubernetes environments consistently after infrastructure starts evolving independently across teams and environments.
That’s where things get messy.
A lot of Kubernetes instability comes from small operational decisions that slowly accumulate over time. A temporary production hotfix becomes permanent because nobody wants to risk changing it later. Resource limits are updated in one environment but forgotten elsewhere. A deployment pipeline evolves gradually while older services continue using previous rollout logic. One cluster receives updated monitoring agents while another still runs older versions.
Individually, these changes are harmless.
Collectively, they create environments that no longer behave the same way.
This is where debugging becomes frustrating because engineers are no longer troubleshooting only applications. They are troubleshooting infrastructure behavior that has slowly drifted over months of operational changes.
And Kubernetes drift is difficult because the platform is extremely dynamic by design. Containers restart constantly. Nodes scale up and down. Services move across infrastructure continuously. Teams deploy changes every day. In environments like that, even small inconsistencies compound surprisingly fast.
The First Real Operational Problem Is Usually Visibility
At smaller scale, engineers usually know what changed recently. If something breaks, the same people who deployed it are often the people investigating it. There’s still enough shared context across the team that troubleshooting remains manageable.
That completely changes once Kubernetes environments grow larger.
Now an engineer trying to debug one production issue may need to check:
- deployment history,
- pod events,
- ingress logs,
- node health,
- runtime metrics,
- autoscaling behavior,
- container resource usage,
- service mesh traffic,
- and monitoring alerts
just to understand whether the issue is actually application-related or infrastructure-related.
And what makes this worse is that Kubernetes itself may still appear perfectly healthy.
Pods are running. Nodes are available. Deployments completed successfully. Cluster health dashboards remain green.
Meanwhile, the application underneath is unstable in ways the infrastructure layer doesn’t immediately expose clearly.
This disconnect between “cluster health” and “actual runtime behavior” is where a lot of Kubernetes operational pain starts.
Experienced SRE teams know this problem very well. It’s why mature Kubernetes operations focus heavily on observability rather than only deployment automation.
Because eventually the biggest challenge is no longer deploying workloads.
It’s understanding what the environment is actually doing in real time.
Production Environments Always Reveal Problems Differently
Production environments have a habit of exposing problems that lower environments never reveal properly.
This happens constantly.
A deployment passes every staging validation check and then starts failing under real production traffic. Autoscaling behaves differently because production load patterns are completely different from testing environments. Network latency suddenly affects service communication timing. A dependency that looked stable during rollout becomes unreliable once thousands of requests start hitting it simultaneously.
Now engineers are trying to determine whether the issue comes from:
- the application itself,
- Kubernetes scheduling,
- runtime resource pressure,
- ingress behavior,
- DNS resolution,
- service discovery,
- or infrastructure changes nobody realized affected production.
This is why experienced infrastructure teams become almost obsessive about environment consistency.
Once production starts behaving differently from every other cluster, deployments stop feeling trustworthy.
And when engineers stop trusting deployments, release velocity slows down automatically. Teams become more hesitant. More manual checks appear. Rollouts become stressful instead of routine.
That operational hesitation is usually a sign that Kubernetes management problems are no longer technical problems alone. They’ve become reliability and operational maturity problems.
Kubernetes Drift Creates Long-Term Operational Confusion
Environment drift is one of the most underestimated problems in Kubernetes operations.
Most drift does not happen because someone made a huge mistake.
It happens because infrastructure evolves gradually.
A manual patch applied during an outage never gets documented properly. One namespace receives updated ingress rules while another still uses older behavior. Resource quotas get adjusted temporarily but remain permanently. Security policies change in one cluster but not others.
Months later, teams are dealing with environments that technically look similar but behave differently in subtle ways.
This creates operational confusion during deployments and incidents because engineers lose confidence in whether environments are actually consistent anymore.
And once deployment consistency disappears, debugging becomes dramatically harder.
Now teams are not only troubleshooting applications.
They are troubleshooting hidden infrastructure differences accumulated over time.
Kubernetes Generates Operational Noise Faster Than Most Teams Expect
One thing people rarely talk about enough is how noisy Kubernetes becomes operationally.
At smaller scale, alerts are useful because they represent real infrastructure issues.
At larger scale, Kubernetes generates constant operational activity:
pod restarts, autoscaling events, failed probes, deployment notifications, node warnings, resource throttling, ingress errors, scheduling delays, and monitoring spikes across multiple clusters simultaneously.
Eventually teams begin mentally filtering alerts because there are simply too many signals happening continuously.
That’s dangerous.
Because once alert fatigue appears, real incidents start blending into normal background infrastructure noise. Engineers stop reacting immediately because most alerts already look familiar even when the underlying issue is much more serious.
This is one of the reasons centralized visibility becomes critical in larger Kubernetes environments. Without structured observability, infrastructure teams spend more time sorting operational noise than solving actual reliability problems.
And over time, that operational fatigue becomes extremely expensive.
Reliable Kubernetes Operations Depend on Consistency
A lot of companies think Kubernetes maturity comes from adding more tooling.
In reality, mature Kubernetes environments usually look boring operationally.
Not because they are simple, but because the teams operating them invest heavily in consistency.
Consistent deployment workflows. Consistent runtime visibility. Consistent rollback handling. Consistent environment management.
That consistency matters far more than having the latest Kubernetes tooling stack.
Because once infrastructure grows large enough, reliability problems almost always come from operational inconsistency rather than missing platform features.
The organizations that run Kubernetes well long-term are usually the ones that standardize operational behavior early, before environment drift and infrastructure fragmentation become difficult to control.
Kubernetes Reliability Is Mostly an Operational Discipline
A lot of Kubernetes discussions online focus heavily on YAML files, Helm charts, or cluster tooling.
But most long-term Kubernetes reliability problems are operational problems.
Teams struggle because:
- environments drift,
- deployment workflows evolve differently,
- visibility becomes fragmented,
- ownership becomes unclear,
- and runtime behavior stops feeling predictable.
Kubernetes amplifies operational inconsistency very quickly because infrastructure changes constantly underneath the surface.
The larger the environment becomes, the more important operational discipline becomes.
And that is usually the real shift organizations experience after operating Kubernetes at scale for long enough.
Kubernetes itself is rarely the hardest part.
Keeping rapidly evolving environments understandable, observable, and predictable is the real challenge.
Recent Posts
- The Hidden Cost of Too Many Dashboards: Why Infrastructure Visibility Gets Harder as Systems Grow
- Why Kubernetes Starts Feeling Unpredictable After a Certain Scale
- Server Deployment Automation: Why Reliable Deployments Become Difficult at Scale
- Modernizing Server Build Workflows for Scalable DevOps Operations
- CI/CD Pipeline Chaos: Why Modern DevOps Teams Need Better Workflow Automation